Link: https://leetcode.com/problems/integer-to-english-words/
Solution:
Topics: math
Intuition
I consider there to be two parts to this problem. The key insight, and then the implementation. The implementation typically writes itself, but in this case there is a very clever trick we can use that will make the code clean.
The key insight is that the number must be processed in adjacent triplets of digits. For example:
num = 200200
word = (two hundred thousand) (two hundred)
if we look at the 3 digits from the end, the number is 200.
the next 3 digits are also 200. The only difference is that the next
triplet represents thousands.
The same rules apply for subsequent triplets (million and billion)
So lets move on to how we can process a triplet of digits. The third digit (from the end) always represents hundreds, the second is tens and the third is ones. There is only one edge case(s)
to worry about, which is if the value of the first two digits is greater than 9 and less than twenty. In that case, the first two digits form ten, eleven, twelve.... And of course adding the units at the end thousand, million, billion.
So the logic is basically solved, but the implementation not as clear. Of course we will need hash maps to convert numbers to words, but what is the best way to process each triplet in the correct order?
My first solution to this problem was to convert the number into a string, reverse it, add leading zeros if needed , and then process each slice of three. For example:
num = 12345
num = '0000012345' #add enough zeros to account for the largest possible number
num = '5432100000' #reverse to simplify the loop
for i in range(0, len(nums), 3): #stride of 3
triplet = nums[i:i+3] #543, 210, 000, 0
#process the triplet...This of course works, but its kind of annoying and riddled with edge cases. The much cleaner and more interesting implementation involves extracting each triplet directly from the number using modulus operations and integer division. How?
num = 1234 #lets get the first triplet 234
part = num % 1000
#we have just removed everything past the 3rd digit. This works for any number.
#part is now equal to 234.
#now we can use integer division to extract the number of Hundreds
hundreds = part // 100
#hundreds is now equal to 2, move on to the tens by modding out the hundreds
part %= 100 #part is now equal to 34
#now lets process the Tens in the same way
tens = part // 10
#tens is now equal to 3
part %= 10 #part is now equal to 4Now we can use this method of processing to build out our parsing logic:
Implementation
def num_to_word(num):
if num == 0:
return 'Zero'
ones = ['', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine']
under_20 = ['Ten', 'Eleven', 'Twelve', 'Thirteen', 'Fourteen', 'Fifteen', 'Sixteen', 'Seventeen', 'Eighteen', 'Nineteen']
tens = ['', '', 'Twenty', 'Thirty', 'Forty', 'Fifty', 'Sixty', 'Seventy', 'Eighty', 'Ninety']
order = ['', 'Thousand', 'Million', 'Billion']
mag = 0
word = ''
while num > 0:
curr = ''
part = num % 1000 #extract 3 digits
if part >= 100:
curr += ones[part // 100] + ' Hundred ' #get hundreds
part %= 100 #remove hundreds
if part >= 10:
if part < 20:
curr += under_20[part % 10] + ' ' #get under 20
part = 0 #remove under 20
else:
curr += tens[part // 10] + ' ' #get tens
part %= 10 #remove tens
if part > 0:
curr += ones[part] + ' ' #get ones
if num % 1000 > 0:
curr += order[mag] + ' ' #add order if needed
mag += 1 #increase order
word = curr + word #add to word
num //= 1000 #remove 3 digits
return word.strip()
#time: o(1)
#memory: o(1)Mnemonic
You have long number in front of you. To delete all digits except the last 3, we cover the rest with a %1000. To delete the last 3 digits, we cover them with a //1000.
Visual
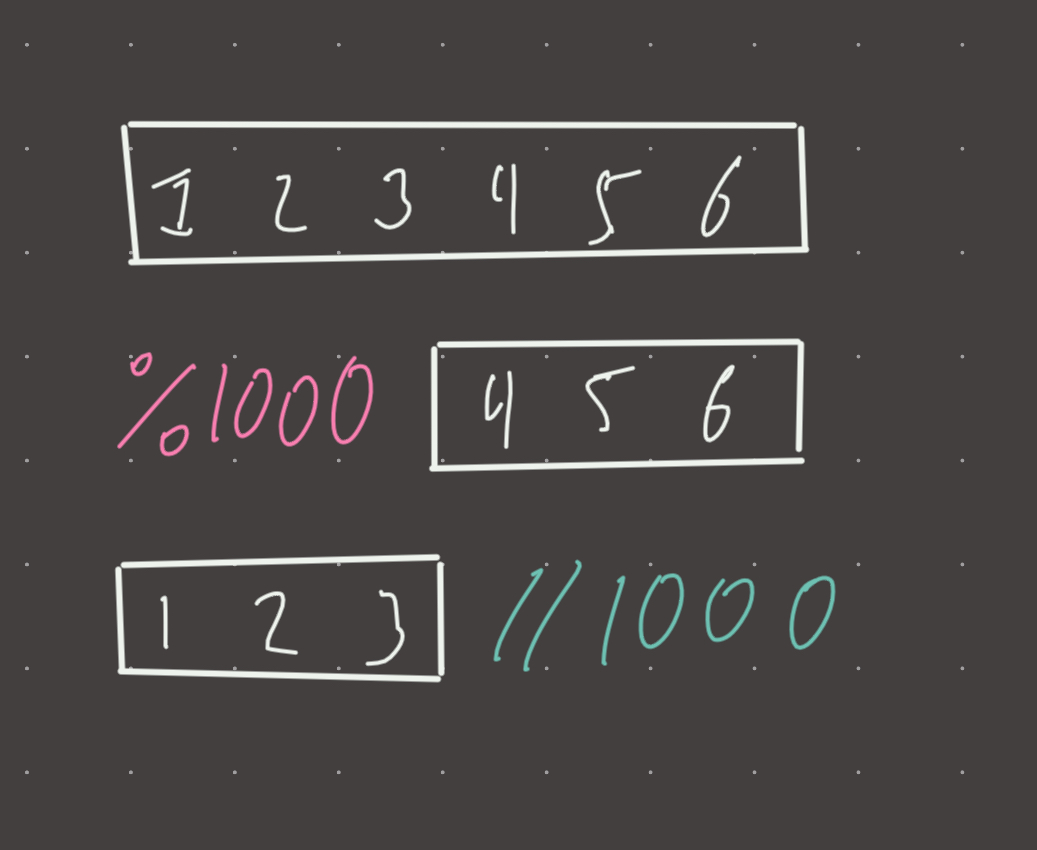
Review 1
Not very difficult algorithmically but the implementation is pretty interesting.
Review 2
Not difficult but super annoying.